XLM 파일 파싱 및 처리 방법, 파이참으로 구조 보기
36_XML 파싱
#data.xml ``` peter 24 elgar 21 hong 36 ``` 위 파일을 다음과 같이 파싱 해보자. ##xml 파 ...
wikidocs.net
기본 처리 방법은 위 링크로 나와 있지만.. 자세히 파악하면!
내 파일의 구조 예시는
<?xml version="1.0"?>
<table>
<survey num="1" title="~">
<question num="1" desc="~">peter</question>
<questionExample desc="~">24</questionExample>
</survey>
<survey num="2" title="~">
<question num="1">elgar</question>
<questionExample id="1" desc="~">21</questionExample>
<questionExample id="2" desc="~">21</questionExample>
</survey>
</table>
- 파이참으로 구조 확인해보기
from xml.etree.ElementTree import parse
tree = parse(path)
table = tree.getroot()
surveys = table.findall("survey")
for survey in surveys:
surveyAttributes = survey.attrib
questions = survey.findall("question")
for question in questions:
questionAttributes = question.attrib
....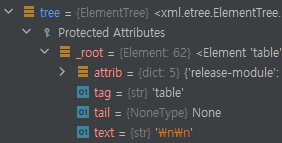
내 tree의 tag는 table이다.
- 태그의 하위 노드 찾기
<table> 태그 안에 하위 태그로 <survey>이 여러개 있으므로,
surveys = table.findall("survey") findall 로 모두 찾고,
for survey in surveys:
하나씩 접근하기 위해서 for문 이용 (같은 방법으로 계속 하위 태그들을 찾아나간다)

table 하고 "." 점만 붙여주면 파이참에서는 어떤 funtion과 module들을 쓸 수 있는지 보여준다
- 노드의 속성값은 딕셔너리 반환
surveyAttributes = survey.attrib
survey 노드의 속성정보를 딕셔너리로 받아온다.
print(surveyAttributes)로 결과 확인하면, {'num':'1', 'title': "~"} 요런식으로 출력.
딕셔너리이기 때문에 각 key의 value 값을 얻고 싶다면, surveyAttributes['num'] 로 '1'을 받을 수 있다.
- 노드 사이 text 값
<question> 태그와 <questionExample> 태그 사이에는 각각 text가 존재한다.

마찬가지로 점 . 을 직어보면 text로 얻을 수 있다는 건 파이참이 친절하게 알려줌
text = question.text
print(text)
#output
peter