<주요 단어 정리>
- positive pair : 원본 sentence 에서 data augmented 한 비슷한 의미인 sentence과의 pair (x, x+)로 나타냄.
supervised learning 에서는 NLI 데이터의 entailment 문장과 원 문장의 pair를 뜻함. - negative pair : 원본 sentence 와 같은 batch 내 의미적으로 다른 sentence들의 pair.
supervised learning 에서는 NLI 데이터의 contraction 문장과 원 문장의 pair를 뜻함. - Isotropy: 벡터가 고르게 분포되어 있는 것
- Anisotropy: 벡터가 고르지 않게 분포 되어 있는 것 (더 자세한 설명은 아래 uniformity와 함께)
※ Point
- Unsupervised Learning 에서 sentence data augmentation 방법으로 drop out 을 사용
- Supervised Learning 에서 SNLI, MNLI 데이터로 entailment 와 contradiction 사용.
(순서와 내용은 본 논문과 조금 다를 수 있음)
1. Background
1.1 previous method
- 기존에는 Data Augmentation을 위해 crop, word deletion, synonym replacement 등을 사용.
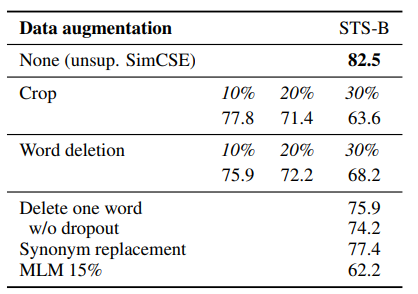
그닥 좋은 방법들이 아님.
- dual-encoder framework 으로 두 개의 independent한 encoder 사용

dual encoder를 사용하는 것보다 하나로 사용하는 것이 더 결과가 좋음
1.2 contrastive learning
contrastive learning 는 간단히 말해서- 의미적으로 비슷한 것은 더 비슷하게, 다른 것은 더 다르게 만드는 것이 목표다.
이 논문에서는 이 개념을 도입한 contrastive framework (A simple framework for contrastive learning of visual representations, Chen et al. (2020), (On sampling strategies for neural network based collaborative filtering, Chen et al., 2017; Henderson et al., 2017)) 을 사용하여 loss 값을 SimCSE을 training objective으로 정의.

이 논문을 이해하고자 한다면 우선 Alignment와 Uniformity에 대해서 이해해야 한다.
1.3 Alignment
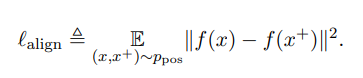
얘는 비교적 이해하기 쉽다. Distance between embeddings of the paired instances.
= paired sentence 사이의 거리
1.4 Uniformity

how well the mebddings are uniformly distributed. 즉, embedding이 얼만큼 embedding space에 균일하게 분포하는지 확인!

모델이 학습을 하면서 점점 embedding 값들이 anisotropic 하게 된다. 이것은 곧 bad uniformity를 의미하는데, 벡터 space 내에서 단어나 문장의 embedding들이 아래 표 처럼 한쪽에 치우쳐져 있는 것이다. 이는 embedding들의 밀집되어 distinctive 하게 표현하는 정도가 떨어지는 것이랑 같은 의미다.
pre-trained된 모델들이 sentence semantic 을 잘 encoding 할지라도 anisotropic 하다는 문제점을 해결해야 함.

2. Model
2.1 Unsupervised - Drop out noise as data augmentation

positive pair
하나의 문장에서 drop out noise로 생성되는 다른 두 개의 sentence embeddings pair.
negative pair
같은 배치 내 의미적으로 다를 수 밖에 없는 문장들 과의 sentence embedding pair.

다양한 p, drop out probability 로 해봤지만, default drop out porbability 인 0.1로 하는게 가장 효과적.
그러나, drop out 이 0 인, 즉 no drop out 과 fixed 0.1(=same drop out masks for pair) 즉, 동일한 문장 임베딩을 output 하는 것은 성능을 매우 떨어뜨림.

align과 uniform을 측정했을 때, 저자들이 제안한 모델★이 alignment를 가장 잘 유지하면서 uniformity 를 낮추는데 효과적.
2.2 Supervised - Entailment and Contradiciton pair

NLI 데이터에는 기준이 되는 문장인 premise와 annotator들이 만든 Entailment, Contradiction, Neutral이 있는데.. 그 중에서 저자는 Entailment가 의미적으로 비슷한 문장으로 보고 positive pair로, contradiction을 반대되는 pair로 사용한다.
예를 들어,
- Premise : There are tow dogs running.
- Entailment : There are animals outdoors.
- Contradiciton : the pets are sitting on a couch
Neutral : the dogs are catching a ball
(premise, entailment) -> positive pair (premise, contradiction) -> negative pair

다양한 dataset 에 positive pair 로 선정하여 비교한 결과, SNLI + MNLI 이 가장 결과가 좋았고 그 이유로는 annotation quality 가 좋고 겹치는 단어(lexical overlap)이 상대적으로 적기 때문이라고 본다.

3. Main Result
BERT 의 token level 모델에서는 CLS token을 sentence embedding으로 사용.

- unsupervised training 에서는 [CLS] representation + MLP 이 가장 효과적.
- supervised SimCSE 에서는 크게 상관 없었음.
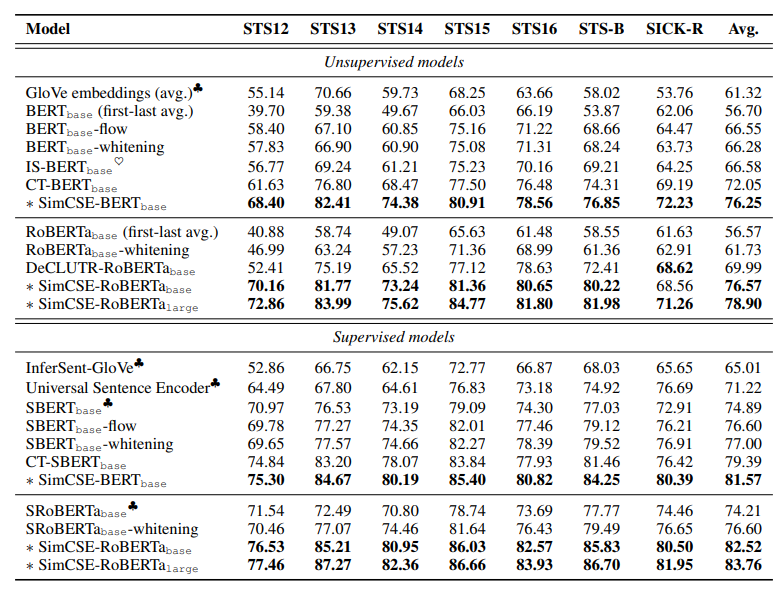
당연히 SimCSE 가 가장 spearsman correlation 에서 높은 점수를 받는다는 결과.
SBert/SRoberta 보다도 좋은 결과를 보이고, 저자는 SimCSE-RoBERTa large가 가장 효과적이었다고 하며 pre-trained 된 모델이 중요성도 언급.
논문 : https://arxiv.org/pdf/2104.08821.pdf
참고 자료 : https://www.youtube.com/watch?v=u-OQVQSvx38&t=623s (다른 어떤 정리글보다도 가장 잘 설명함.. 역시 저자이자 프린스턴, 그리고 나름 알아듣기 쉬웠던 영어발음)