논문 정리 요약본
- Error Analysis of Statistical Machine Learning Translation Output
- Translation Quality and Error Recognition in professional neural machine translation post-editing
- Error detection and error correction for improving quality in machine translation and human post-editing
목적 : MT 오류 유형 분석
1.Error Analysis of Statistical Machine Learning Translation Output
[세부 내용 정리]https://joannekim0420.tistory.com/33
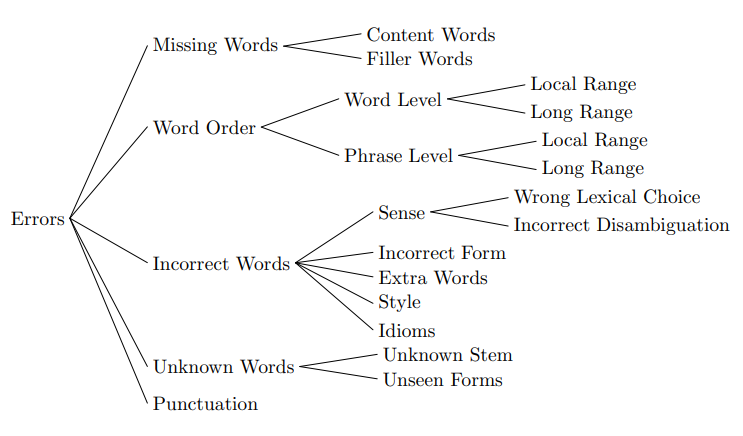
ERROR 유형들을 5가지(missing words, word order, Incorrect words, Unknown Words, Punctuation)로 분류함.
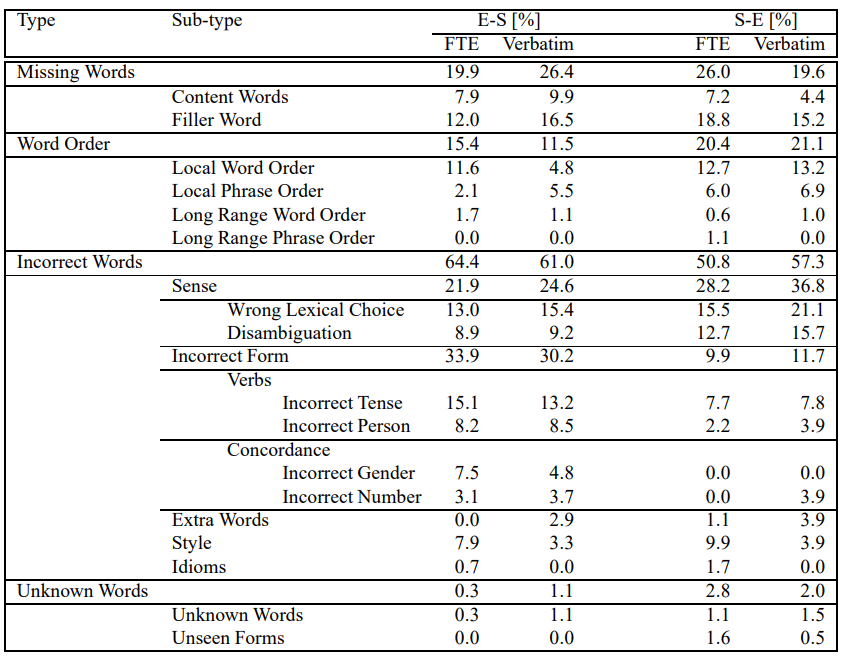
ENGLISH to SPANISH
- Incorrect Words (64.4%)
-Sense (21.9%) → 의미변절
>Wrong Lexical Choice (13.0%)→ 의미 오번역
>Disambiguation (8.9%) → 의미 불명확한 경우
-Incorrect Form (33.9%) → 단어 형태가 맞지 않는 경우 (굴절어에 더 민감)
>Incorrect Tense (15.1%) → 스페인어의 경우 17가지의 verb tense 존재(굴절어 특징)
>Incorrect Person → 문장이 길어지면서 동사가 대응되는 주어를 찾지 못했을 때
>Incorrect Gender&Number → 관사와 형용사는 gender 와 명사 개수에 맞아야 함. - Missing Words (19.9%)
-Content Words(7.9%) → 의미 표현에 중요 단어(noun, verb etc)가 빠진 경우
-Filler Words(12.0%) → 문법적인 요소일 뿐, 의미는 유지되는 경우 - Word Order (15.4%) → 영어 adj-noun / 스페인어 noun-adj 순서
-Local Word Order(11.6%) → 시스템이 찾지 못한 adj-noun pair 또는 더 긴 문장을 reordering 하는 경우
SPANISH to ENGLISH → 스페인어에 비하면 영어는 비교적 덜한 굴절어라 ENES보다 오류율이 조금 낮음
- Incorrect Words(50.8%)
-Sense
>Wrong Lexical Choice (18.5%)
-Incorrect Form(9.4%) - Missing Words(27.5%)
-Content Words(22.1%)
-Filler Words(5.4%) - Word Order(17.8%)
- Extra Words(17.8%)
-Content words(5.4%)
-Filler Words(12.4%)
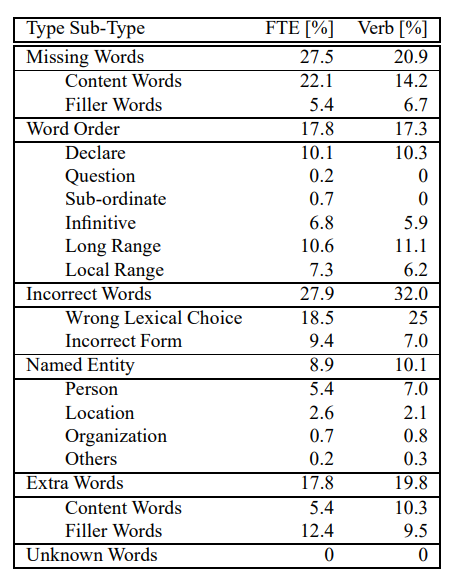
CHINESE to ENGLISH → 수식어구의 위치가 다르다는게 두 언어의 차이
- Incorrect Words(27.9%)
-Sense(28.2%)
>Wrong Lexical Choice (15.5%)
>Disambiguation (12.7%)
-Incorrect Form(9.9%) - Missing Words(26.0%)
-Content Words(7.2%)
-Filler Words(18.8%) → filler words 의 비중이 높아 의미 보존 된 sentence는 많음 - Word Order(20.4%)
-Local Word Order (12.7%)
2.Translation Quality and Error Recognition in professional neural machine translation post-editing
[세부 내용 정리] https://joannekim0420.tistory.com/31
- lexical errors 에 초점을 둠
- Hjerson = automatic MT error Analysis

- WER = Word Error Rate
- RPER = position-independent error rate in the reference (source)
- HPER = position-independent error rate in the hypothesis (target)
- inflectional error
a word whose full form is marked as RPER/HPER error but the base forms are the same - reordering error
a word which occurs both in the reference and in the hypothesis is thus not contributing to RPER or HPEr but is marked a WER error - missing word
a wrod which occurs as deletion in WER errors and at the same time occurs as RPER error without sharing the base form with any hypothesis error - extra word
a wrod which occurs as insertion in WER errors and at the same time occurs as HPER error without sharing the base form with any reference error - incorrect lexical choice
a word which belongs to neither to inflectional errors nor to missing or extra word is considered as lexical error
- NMP = machine translation 결과
- NMTPE = NMP 결과를 1번 전문가가 post-editing 한 결과 (오류가 남아 있는 경우는 오류를 놓치거나 오류를 옳게 수정하지 않은 경우)
→ lexical errors 가 대부분을 차지.
→ lexical error 와 extra word 를 구분하기 모호해 둘을 합친 후 세부 유형을 MQM 프레임워크 기반으로 오류 유형을 나눔

- REV = NMTPE 를 전문가가 다시 수정한 결과
→ 오류가 아닌 이슈로 classification 함(위 기준대로 수정한다고 해도 모두 실제 번역 오류라고 볼 수 없음)
→ 총 6개의 기준(Mistranslation, Terminology, Unidiomatic, Register, Spelling, Function words) 으로 분류
- Mistranslation
the target content does not accurately represent the source content
→ 오번역, tgt이 src의 의미를 제대로 번역 못한 경우 - Terminology
a term (domain specific word) is translated with a term other than the one expected for the domain or otherwise specified
→ domain이 정해진 단어가 같은 도메인으로 번역되지 않은 경우 - Unidiomatic
The content is grammatical, but not idiomatic
→ 문법적으로 틀리진 않지만, 원어민이 느끼기에 자연스럽지 못한 경우 - Register
The text uses a level of formality higher or lower than required by the specifications or general language conventions
→ 언어 규칙에 맞지 않는 존대, 낮춤 사용한 경우 - Spelling
Issues related to spelling of words
→ 철자 관련해서 틀린 경우 - Function words
A function word (preposition, helping verb, article, etc) is used incorrectly
→ 전치사, 관형사, 등등이 옳게 쓰이지 않음
3.Error detection and error correction for improving quality in machine translation and human post-editing
[세부 내용 정리]https://joannekim0420.tistory.com/30
MQM framework + TAUS document 바탕으로 7가지(Accuracy, Fluency, Style, Terminology, Wrong language variety, Named entities, Formatting and encoding errors) 오류로 나누고
가장 에러 비율이 높은 비중을 차지하는 Fluency Error 중 Word Order in noun modification structures 에 집중해서 살펴봄.
ENGLISH Detection WARNING to human editors
- RULE 1
when a named entity occurs in the target text and is preceded or followed by an adjective or a PP that modifies it
(ADJP|PP) + PROPN → warning
PROPN + (ADJP|PP) → warning - RULE 2
When a named entity occurs in the target text within a PP as a modifier
N + modifiesP + PROPN → warning - RULE 3
If a noun or a PP preced the head noun
(N|PP)+N → warning - RULE 4
If one of the sequences listed below are detected
N + N → warning
N + ADJ+ +N → warning
ADJ+ + N + M → warning
ADJ + ADJ+ + N + N+ → warning
ENGLISH CORRECTION
- RULE 5
If an adjective modifying a noun in English and the adjective is a quality adjective, then the order in the target language should be noun adjective
ADJQ + N → N + ADJQ - RULE 6
If a noun preceding another noun in English, and the first noun modifies the second, invert the order and convert the noun into an adjective phrase or a PP
N1 + modifiesN2 → N2 +(ADJP|PPN1)
ITALIAN DETECTION WARNING to human editors
- RULE 7
if a noun ending in a consonant occurs in the target text, check if its specifiers and modifiers are masculine.
SPR* + N_consonant + MOD* → SPR*masc + N_consonant + MOD*masc - RULE 8
if a noun ending in an -s occurs in the target text, check if it is a foreign word in plural form. - RULE 9
when a named entity occurs in the target text co-occuring with specifiers and modifiers, ask the editor to check the agreement between all these elements
SPR* + MOD* +PROPN + MOD* → warning - RULE 10
if the quantifier "nessuno" or "chiunque" are part of the subject of a sentence, ask the editor to check if the head verb form of the sentence is singular
ITALIAN CORRECTION
- RULE 11
if a noun ending in "-tore" occurs in the target text, then its specifiers and modifiers are masculine
SPR* + N_tore + MOD* → SPR*masc + N_tore + MOD*masc - RULE 12 (Itlalian)
if a noun ending "-ta","-tu","-trice","-tite' or "-zione" occurs in the target text, then its specifiers and modifiers are feminine.
SPR* + N_ta | tu | -trice | -tite | -zione + MOD* → SPR* + N-ta + MOD*fem
- Error Analysis of Statistical Machine Learning Translation Output
- Translation Quality and Error Recognition in professional neural machine translation post-editing
- Error detection and error correction for improving quality in machine translation and human post-editing